CVMI Lab
Computer Vision and Machine Intelligence
The University of Hong Kong


News
Our Research
Our Research
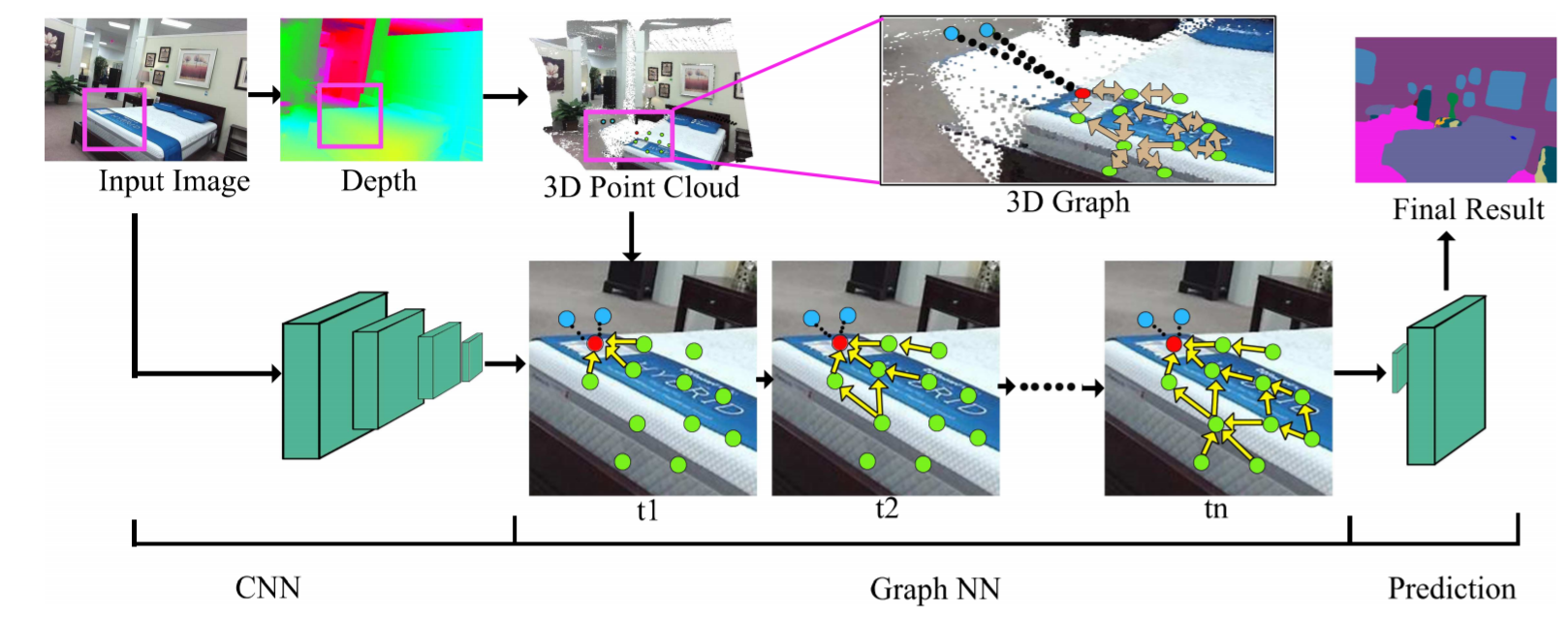
Our research aims at endowing machines with the capability to perceive, understand, and reconstruct the visual world with the following focuses:
- developing scalable computation-efficient and label-efficient deep learning algorithms for natural and medical image analysis;
- designing effective techniques for 3D scene understanding and reconstruction;
- building lifelong learning machines that can learn continuously, transfer previous knowledge adn discover novel concepts (through interaction).